
初代 – 關聯性資料庫
舊有的搜尋機制是透過傳統Relational Database的分數欄位和文字索引實踐搜尋,利用特定條件的商品搜尋分數的計算後,放進資料庫當中,利用資料庫的搜尋索引來實踐商品搜尋。
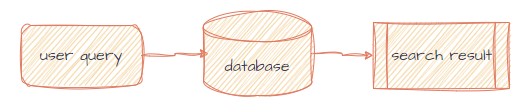
然而,排程定期更新搜尋資料庫商品資訊以及分數的方式會產生部分問題:
- 分數的更新頻率跟準確性無法確實掌控,使分數準確度處於一個無法確認的狀態
- Database在對文字索引查詢上的效能不彰,也是另一個問題
因此,最初代以Database為基礎的搜尋機制,被後來新起之秀Search Engine取代。
二代 – 搜尋引擎
Search Engine中,比較熱門的是open project的Apache Solr以及商用Elastic search,目前這邊倆的引擎核心部分都是 Apache Lucene,Apache Solr 跟 Apache Lucene 則是差不多一起更新的Open Project,而露天選用Apache Solr。
Search Engine的引入,大大的增加其文字索引效能不彰的問題,Apache Solr 的 Solr Cloud 機制解決了很多擴充性上的問題,基於上億document(在database上稱為row)的查詢上,有很好的可用性。
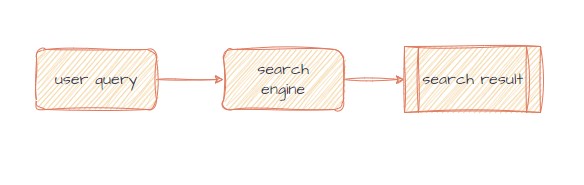
初代和二代的結構上,都只能透過調整query 的公式來進行搜尋結果上的調整,而且往往query 公式很單一,用一個query 是無法滿足全部的狀況,特別是露天這種商品各種種類跟屬性都有的狀況。
所以,露天繼而發展出query regenate的架構:透過事前分析,將搜尋引擎資料分群,給予不同使用者、不同場景,能使用不同的搜尋語法(群體化)。
此外,露天搜尋引擎除了原本初代有的基本商品計分外,還擴充取用露天平台上使用者資訊加入回饋,資訊包括「會員」、「賣家」、「關鍵字」、商品」四個面向進行分析,並提取各面向的因子加入搜尋系統和推薦系統,進行應用。
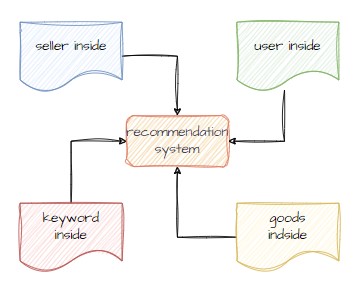
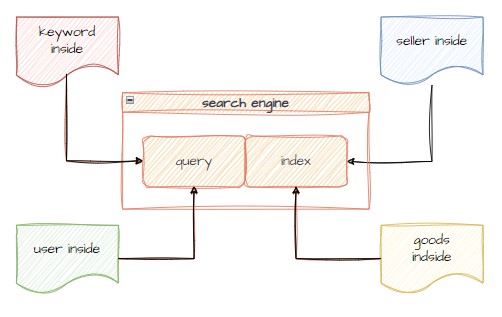
露天二代搜尋進階版,除了基礎的關鍵字或指定欄位索引搜尋外,也包含關鍵字推薦商品的結果,也就是整合了「推薦系統」與「關鍵字/特定欄位搜尋結果」的內容,形成新的搜尋結果。此外,還透過「個人化預測排序」跟套用「商用邏輯」再次優化,得到最終的結果。
然而,在基於現有使用者行為反饋進行分析得到的因子,仍有其弱點:收集的資訊過於集中於某個群體時,表現出的結果有其偏頗,例如:在群體分布在男性用戶多於女性用戶的情況,於較中性的關鍵字上,就會偏向男性的商品結果。
在這種情況下就必須要進行修正,而如何建立判斷結果是否偏頗?是否需修正?也需再透過大資料分析。因此,露天搜尋系統加上更多的資料分析模組,繼而產出下一代的AI推薦搜尋。
露天搜尋引擎指南
露天經過數年的搜尋經驗累積與分析過巨量的商品、買家行為,整理出一些讓賣家參考的指南,可幫助賣家提升商品曝光率,讓買家能夠精準搜尋到需要的、想要的、有吸引力的商品。
建議來露天平台的賣家,認真遵循「露天搜尋引擎指南」的建議來設定商品的命名、分類、售價、庫存等調整,能有效幫助來逛街的消費者,能更精準有效的找到您的商品。

文章撰寫:真肉 責任編稿:忠編
那些年 我在露天學會的事
露天工程師:
露天搜尋變革以及演進

